안녕하세요! 데이터로 일하는 데이터엔지니어스랩입니다👋👋
지난번에 미세먼지 데이터 수집에 대해 포스팅했었는데요, 데이터엔지니어스랩은 사내 DB에 미세먼지 데이터를 포함한 많은 데이터를 파이프라인을 통해 수집하고 있습니다. 데이터들이 항상 정상적으로 수집되면 좋겠지만 그렇지 않은 경우도 종종 있었습니다.
파이프라인의 숫자가 적었을 때는 일일이 체크하는 것이 쉬웠지만 그 숫자가 점점 증가하면서 작업이 점점 부담되기 시작했습니다. 그래서 이를 해결하기 위해 모니터링 시스템을 구축하기로 했습니다. 오늘은 저희가 구축했던 파이프라인 모니터링 시스템 구축하며 겪었던 경험을 공유해 드리려고 합니다.
문제 상황 인식

기존에는 데이터 수집이 잘 되고 있는지, 수집이 안 되는 원인 파악을 매주 금요일 Airflow 및 n8n execution/log를 확인하며 체크하고 이상 유무를 판단했습니다. 이상이 있을 시 관리자는 오류를 수정하고 이후 관련 내용을 작성하여 Teams로 공유했습니다. 그러다 보니 두 가지 문제점이 발생했습니다.
- 관리자가 매주 직접 파이프라인을 확인해야 함
- Teams 메세지로 직접 오류 상황을 공유해야 하는 번거로움
그래서 한눈에 파이프라인들을 모니터링하고 팀에 공유하는 작업을 조금 더 간소화하자는 취지에서 시작하게 되었습니다.
해결하기
모니터링 시스템을 구축하는 방법은 여러 가지 있습니다. 그중에서 저희는 파이썬과 스트림릿을 사용하여 구현하는 방법을 선택했습니다.
Streamlit 이란

Streamlit은 파이썬으로 작성된 오픈소스 라이브러리로, 데이터 분석 및 시각화, 머신러닝 모델을 활용한 인터랙티브 웹 애플리케이션을 손쉽게 만들 수 있도록 도와주는 도구입니다. 웹 개발에 대한 지식이 없어도 순수 Python 코드만으로 데이터 분석 결과를 시각적으로 표현할 수 있어, 데이터 사이언티스트나 분석가에게 매우 유용한 프레임워크입니다.
기본적으로 파이썬을 사용하고 있어서 필요 라이브러리 import, def 함수를 사용하여 main 함수에 포함하면 원하는 페이지를 만들 수 있습니다. 무엇보다 가장 큰 특징은 파이썬 코드만으로 프론트엔드 부분과 백엔드 부분을 모두 구현할 수 있다는 점입니다.
1. 환경설정
- 패키지 설치
pip install streamlit # streamlit 패키지 설치
pip install streamlit-authenticator # 로그인 기능을 위해 설치로그인과 관련된 아이디와 비밀번호, 쿠키 정보는 아래 패키지 구조의 config.yaml에 설정해 주었습니다.
2. 패키지구조

- /streamlit/app : 로그인 기능과 기본 화면 구조를 담당
- /streamlit/app/app_pages : 비즈니스 로직 구현을 담당
모니터링 화면을 위해 sample 페이지를 제외한 pipeline_pg.py 만 사용했습니다.
3. 어플리케이션 실행

Terminal로 app.py 가 있는 경로를 설정하고 streamlit run app.py 명령어 실행하면 기본적으로 브라우저에서 localhost:8501 주소로 앱이 열리며, 배포 환경에서는 지정된 도메인 주소로 접근할 수 있습니다.
참고 문서
기본적으로 streamlit 라이브러리에 설치되어 있는 라이브러리는 공식 문서에서 확인할 수 있습니다. Streamlit 은 최근에도 새로운 버전이 릴리스 되고 있고 공식 문서도 보기 편하게 되어있는 편이라 공식 문서만으로도 충분히 구현이 가능합니다.
Streamlit Docs
Join the community Streamlit is more than just a way to make data apps, it's also a community of creators that share their apps and ideas and help each other make their work better. Please come join us on the community forum. We love to hear your questions
docs.streamlit.io
기존에 streamlit이 제공하지 않는 기능을 여러 개발자가 만들어 놓은 라이브러리인 Third-Party-Components 도 있습니다. 기본으로 제공하지 않는 LLM, Chart, Widget 등 원하는 기능을 검색하여 설치하여 활용도를 더 높이고 나만의 어플리케이션 개발이 가능합니다.
단, Streamlit 버전과 새로 추가된 라이브러리와 버전 충돌을 방지해야 하므로 버전 체크는 필수입니다!
Components • Streamlit
Streamlit is an open-source Python framework for data scientists and AI/ML engineers to deliver interactive data apps – in only a few lines of code.
streamlit.io
사내 데이터 파이프라인 현황 구현 및 코드
1. 라이브러리 설치
사내 데이터 파이프라인 모니터링 화면 구현을 위해 Python == 3.12 및 아래 requirements를 설치했습니다.
streamlit==1.42.1
streamlit-authenticator==0.4.1
streamlit-elements==0.1.0
streamlit-option-menu==0.4.0
numpy==2.2.3
pandas==2.2.3
mysql==0.0.3
SQLAlchemy==2.0.38
plotly==6.0.0
pytz==2025.1
pyyaml==6.0.2
python-dotenv==1.0.0
psycopg2-binary
2. 로그인 기능 코드
인증 인가 구현 부분입니다. 아이디와 비밀번호는 config.yaml 파일에 미리 만들어 놓은 계정으로 로그인이 가능합니다.
# import library
import streamlit as st
import pandas as pd
import numpy as np
import time
import os
import base64
from pathlib import Path
import streamlit as st
import yaml
from yaml.loader import SafeLoader
import streamlit_authenticator as stauth
from sqlalchemy import create_engine
from app_pages.common_func import main_page_style
from app_pages.pipeline_pg import show_0
# from app_pages.sample_pg01 import show_1
# from app_pages.sample_pg02 import show_2
# from app_pages.sample_pg03 import show_3
# 경로 설정
current_path = os.path.dirname(os.path.realpath(__file__))
dlab_logo_path = os.path.join(current_path, "./images/dlab_logo.png")
# 페이지 기본 설정
st.set_page_config(page_title="DLAB. 파이프라인현황", layout="wide", initial_sidebar_state="expanded", ) #page_icon="🌀")
# 푸터 HTML 생성 함수 (이전과 동일)
def footer_html(img_path):
img_bytes = Path(img_path).read_bytes()
img_base64 = base64.b64encode(img_bytes).decode()
footer_template = f"""
<div class="login-footer">
<img src="data:image/png;base64,{img_base64}" alt="DLAB Logo" >
<div class="login-footer-text">
ⓒ 2025 DATA ENGINEERS LAB CO., Ltd.
</div>
</div>
"""
return footer_template
# 로그인 기능 (수정됨)
def login_action(authenticator):
try:
authenticator.login(fields={'Form name': 'Login', 'Username': '아이디', 'Password': '비밀번호', 'Login': '로그인'})
if st.session_state['authentication_status']:
st.sidebar.write(f'🦄 **{st.session_state["name"]}** 님, 환영합니다.')
# 로그아웃
if authenticator.logout('로그아웃', location='sidebar'):
st.session_state.clear() # 세션 상태 초기화
st.rerun()
except Exception as e:
print('로그인 에러: ', e)
pass

3. Sidebar 및 메인 함수 코드

# sidebar markdown 설정
def page_step1_side_info():
st.sidebar.divider()
st.sidebar.markdown("##### ⏰ Scheduled")
data = get_pipeline_table()
# 🔹 'airflow'인 데이터만 필터링
airflow_data = data[data["service"] == "airflow"]
if airflow_data.empty:
st.sidebar.write("❌ Airflow 관련 스케줄이 없습니다.")
else:
with st.sidebar.expander("🔁 Airflow", expanded=False):
for _, row in airflow_data.iterrows():
st.markdown(f"📌 **{row['pipeline_name']}**: {row['schedule']}")
# n8n 데이터스케쥴
n8n_data = data[data['service']== 'n8n']
if n8n_data.empty:
st.sidebar.write("❌ Airflow 관련 스케줄이 없습니다.")
else:
with st.sidebar.expander("🔄N8N", expanded=False):
for _, row in n8n_data.iterrows():
st.markdown(f"📌 **{row['pipeline_name']}**: {row['schedule']}")
st.sidebar.divider()
st.sidebar.markdown("##### ⚙️ Description")
data = get_pipeline_table_data()
# 🔹 `pipeline_name`별 그룹화
pipeline_names = data['pipeline_name'].drop_duplicates()
for pipeline in pipeline_names:
pipeline_data = data[data["pipeline_name"] == pipeline]
if pipeline_data.empty:
st.sidebar.write(f"❌ '{pipeline}' 관련 테이블이 없습니다.")
else:
with st.sidebar.expander(f"🚀 {pipeline}", expanded=False):
for _, row in pipeline_data.iterrows():
st.markdown(f"📌 **{row['table_name']}**: {row['description']}")
# 메인 함수
def run_main():
try:
# 메인페이지 공통 CSS
main_page_style()
# 사이드바 로고 추가
# st.logo(image='images/horizontal_new-removebg-preview.png', icon_image='images/icon_new-removebg-preview.png')
# 계정 셋업
authenticator = login_access_setup()
# 로그인 페이지
login_action(authenticator) # 로그인 함수 실행 (세션 변수에 결과 저장)
# 현재 상태 출력
# st.markdown(f"**Logged In**: {st.session_state['authentication_status']}") # None or True
# print(st.session_state)
# 인증 상태에 따라 다른 페이지 구성
if st.session_state.get('authentication_status'):
# 로그인 성공: selectbox를 사용하여 페이지 전환
page = st.sidebar.selectbox("📁 **Go to**", ["사내 파이프라인 현황"], key="page_select")
# 페이지 selectbox 추가시, "이름", 추가
if page == "사내 파이프라인 현황":
page_step1_side_info()
show_0()
# if page == "STEP 1. 페이지":
# page_step1_side_info()
# show_1()
# elif page == "STEP 2. 페이지":
# # page_step2_side_info()
# show_2()
# elif page =="STEP 3. 페이지":
# show_3()
elif st.session_state['authentication_status'] is False:
st.error('아이디 혹은 비밀번호가 맞지 않습니다.')
elif st.session_state['authentication_status'] is None:
st.warning('아이디와 비밀번호를 입력하세요.')
if st.session_state.get('authentication_status') is not True:
st.markdown(footer_html(dlab_logo_path), unsafe_allow_html=True)
except Exception as ex:
print(f'메인페이지 에러 : {ex}')
pass
if __name__ == '__main__':
run_main()- DB에 저장된 정보를 읽어와서 현재 실행되고 있는 파이프라인의 정보
- 파이프라인별 schedule 시간
- 데이터의 업데이트 시간과 어떤 데이터를 수집하고있는지

3. 모니터링 화면 코드
import streamlit as st
import pandas as pd
from sqlalchemy import create_engine
import streamlit.components.v1 as components
import yaml
import altair as alt
import re
import time
import datetime
import pytz
def show_0():
st.markdown ('### 파이프라인 현황')
with st.container(border=True):
data = transform_data()
components.html(data, height=500, scrolling=True)
st.markdown('### 히스토리')
with st.container(border=True):
# 한국 표준시(KST) 가져오기
kst = pytz.timezone('Asia/Seoul')
today_kst = datetime.datetime.now(kst).date() # KST 기준 날짜
two_weeks_ago_kst = today_kst - datetime.timedelta(days=14)
# 사용자 날짜 선택 (최근 2주 기본값 설정)
selected_date_range = st.date_input(
"날짜 선택 (최근 2주 기본값)",
value=(two_weeks_ago_kst, today_kst),
min_value=None,
max_value=None,
key="date_input_recent_2weeks"
)
# 선택한 날짜 범위 적용
if isinstance(selected_date_range, tuple):
min_date, max_date = selected_date_range
else:
min_date = max_date = selected_date_range
# 데이터 불러오기
fail = error_test_data(min_date, max_date, state=2)
warn = error_test_data(min_date, max_date, state=1)
success = error_test_data(min_date, max_date, state=0)
# 상태별 데이터 매핑
data_list = [("🔴 실패", fail, 2, "fail"), ("🟡 경고", warn, 1, "warn"), ("🟢 성공", success, 0, "success")]
with st.container(border=True):
col1, col2, col3 = st.tabs([d[0] for d in data_list]) # 탭 생성
for idx, (tab_name, data, state_value, key_prefix) in enumerate(data_list):
with (col1 if idx == 0 else col2 if idx == 1 else col3):
if not data.empty:
# 페이지 변경 UI
bottom_menu = st.columns((4, 1, 1))
with bottom_menu[2]:
# 페이지 크기 선택 (기본값: 10)
batch_size = st.selectbox("페이지 크기", options=[10, 25, 50], key=f"{key_prefix}_batch")
# 전체 페이지 수 계산
total_pages = max(1, (len(data) // batch_size) + (1 if len(data) % batch_size > 0 else 0))
# 현재 페이지 상태 저장 및 초기화
if f"{key_prefix}_page" not in st.session_state:
st.session_state[f"{key_prefix}_page"] = 1
current_page = st.session_state[f"{key_prefix}_page"]
with bottom_menu[1]:
new_page = st.number_input("페이지", min_value=1, max_value=total_pages, step=1, key=f"{key_prefix}_page_input")
if new_page != current_page:
st.session_state[f"{key_prefix}_page"] = new_page
st.rerun() # 페이지 변경 시 UI 업데이트
# 페이징된 데이터 가져오기 (데이터 변경 반영)
pages = split_frame(data, batch_size)
paginated_data = pages[current_page - 1] # 현재 페이지 데이터
# HTML 테이블 표시 (페이징된 데이터 적용)
st.html(df_to_html_table(paginated_data))
st.markdown(f"Page **{current_page}** of **{total_pages}** ")
else:
st.write(f"{tab_name} 내역이 없습니다.")
st.markdown('### 테이블별 데이터 변화')
with st.container(border=True):
# 한국 표준시(KST) 가져오기
kst = pytz.timezone('Asia/Seoul')
today_kst = datetime.datetime.now(kst).date() # KST 기준 날짜
# 가장 최신 확인일자의 데이터 조회 (중복 제거)
today_str = today_kst.strftime('%Y-%m-%d')
latest_data = check_rows(today_str)
# 최근 30일간의 데이터 변화 추이 가져오기 (중복 제거)
trend_data = get_table_trend()
trend_data = trend_data.fillna(0)
if latest_data.empty:
st.write("📢 조회된 데이터가 없습니다.")
else:
# 테이블별 30일간 데이터 변화량 계산
trend_dict = {}
total_trend_dict = {}
for table_name in latest_data["테이블명"].unique():
table_trend = trend_data[trend_data["table_name"] == table_name]
trend_dict[table_name] = table_trend["table_rows_difference_day"].tolist()
total_trend_dict[table_name] = table_trend["this_day_table_rows"].tolist()
# DataFrame 복사 후 LineChartColumn 추가
df = latest_data.copy()
df["views_history"] = df["테이블명"].map(trend_dict)
df["total_history"] = df["테이블명"].map(total_trend_dict)
type_labels = ["type4", "type3", "type2", "type1"]
type_explanations = {
"type4": "#### 월간 데이터",
"type3": "#### 정기 데이터 (공휴일 영향을 받지 않음, 주간/일간)",
"type2": "#### 정기 데이터 (공휴일 영향을 받음)",
"type1": "#### 비정기 데이터"
}
type_data = {t: df.query("타입 == @t") for t in type_labels}
with st.container(border=True):
col_tabs = st.tabs(['월간 데이터', '정기 데이터(공휴일 영향 X)', '정기 데이터(공휴일 영향 O)', '비정기 데이터'])
for tab, type_name in zip(col_tabs, type_labels):
with tab:
type_df = type_data[type_name]
if not type_df.empty:
type_df = type_df.drop("타입", axis = 1)
st.dataframe(
type_df,
column_config={
"views_history": st.column_config.LineChartColumn("최근 30일 데이터 변화량",y_min=0),
"total_history": st.column_config.LineChartColumn("30일 전체 데이터 추이", y_min=0),
}, use_container_width=True, hide_index= True
)
else:
st.write(f"{type_name} 데이터가 없습니다.")
- 파이프라인 현황 - 신호등
- 히스토리
- 테이블별 데이터 변화
1. 파이프라인 현황 ("신호등")
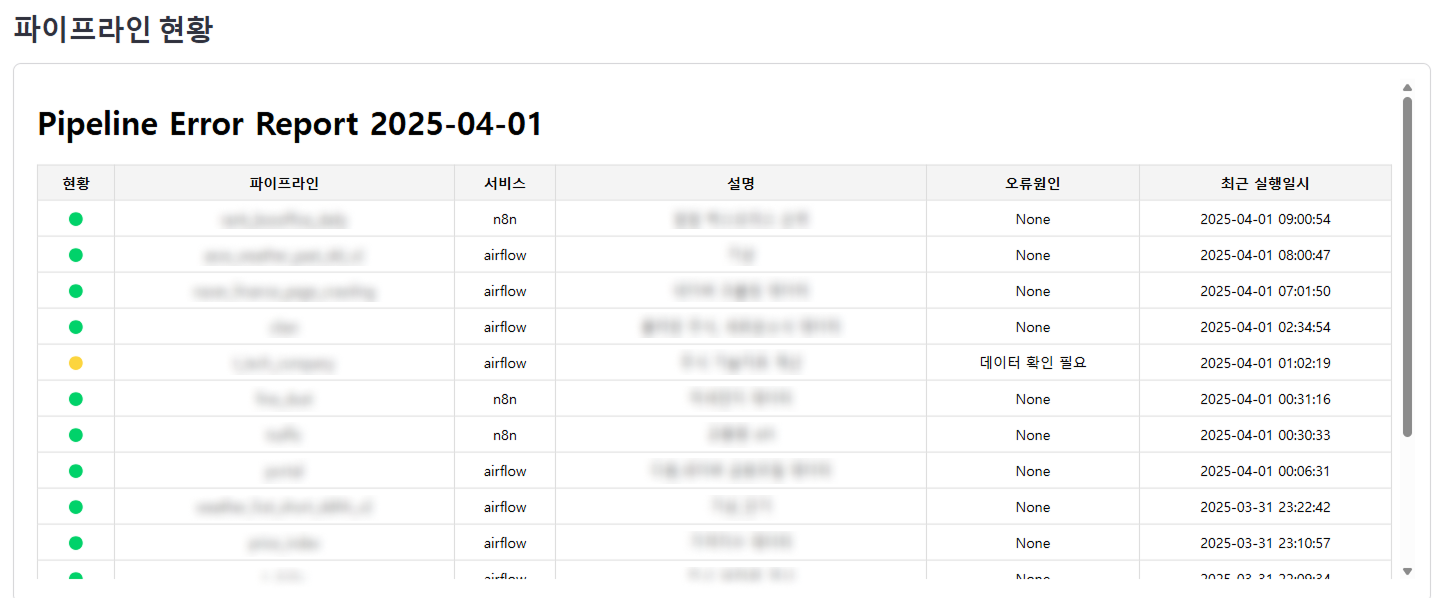
기존 시스템의 문제점은 관리자가 직접 로그를 분석하며 모니터링해야 한다는 점이었습니다. 이 문제를 해결하기 위해 워크플로우 자동화 서비스인 n8n을 사용하였습니다.
n8n 워크플로우를 통해 파이프라인의 상태를 보여주는 "신호등" 메세지와 table별 rows의 변화량 조건의 데이터를 db에 저장하고 화면에 보여주는 작업과 파이프라인 현황 메세지를 Teams에 보내는 것 모두 자동화할 수 있었습니다. 이제 관리자는 일일이 로그를 분석할 필요 없이 모니터링 화면을 보는 것만으로도 모든 파이프라인의 상태 체크와 오류 상황 공유가 가능해졌습니다.
수정이 필요하다면 화면과 메세지를 보고 작업할 수 있게 구현하여 빠른 오류 대응이 가능하게 구현하였습니다.
2. 히스토리

신호등의 빨간불, 노란불, 초록불을 실패, 경고, 성공으로 나누었으며, 위에 사진과 같이 파이프라인별 오류를 확인하고, 그 오류 로그를 확인할 수 있게 바로 airflow / n8n 오류 로그가 있는 링크로 갈 수 있습니다.
히스토리는 오늘 날짜 기준 2주간 데이터를 기본적으로 표시되고, 날짜를 선택하여 확인할 수 있습니다. 주로 빨간불과 노란불에 있는 내용을 확인하여 수정하고 다음날 같은 오류가 없으면 해결된 것으로 판단하였습니다.
* 히스토리 : 실패

* 히스토리 : 경고

모니터링 시스템을 개선할 때 잡았던 목표 중 두 번째 목표인 오류 상황 공유는 n8n의 OpenAI 노드를 사용했습니다.
파이프라인별 스케줄 된 시간에 workflow가 작동했을 때, n8n에 연동된 webhook을 통해 Airflow에선 log history, n8n에선 execution error 정보를 보내고, n8n의 OpenAI 노드를 활용하여 log를 요약해서 저장합니다. 에러 발생 시 로그를 Chat GPT가 요약하여 저장하는 순서는 아래와 같습니다.

내용요약을 하기 위해서는 GPT에게 promt를 날려야 합니다. 모니터링 화면에 요약본 promt와 GPT의 content 설정은 아래와 같이 해주었습니다.

content에서 GPT가 조금 더 전문적인 방향성으로 요약본을 만들어 내기 위해서 content 값의 설정이 필요합니다. 또한, 원하는 return 값도 설정해 주셔야 합니다. 이는 gpt_format 노드에서 설정해 주었습니다.


이렇게 설정하고 에러 발생 시, 저장된 오류 요약본을 모니터링 화면에서 볼 수 있게 구현했습니다. 실제 에러 발생했을 때 GPT가 요약한 내용입니다.

3. 테이블별 데이터 변화

파이프라인에 수집되고 있는 테이블별 총 데이터 수, 데이터 변화량은 파이썬 라이브러리 Pandas를 이용하여 구현을 했습니다. Dataframe 을 사용하여 데이터 수와 rows 변화량 추이, 전체 데이터량을 육안으로 확인하여 특이점을 분석할 수 있게 구현했습니다. 또한 st.column_config.LineChartColumn 을 활용하여 기본적인 라인 차트를 넣을 수 있습니다.
DataFrame 은 파이썬의 pandas 라이브러리에서 사용하는 2차원 표 형태의 데이터 구조입니다.
쉽게 말해 엑셀 표처럼 행과 열로 이루어진 데이터 테이블을 코드로 조작할 수 있게 해주는 데이터 구조입니다.
완성된 모니터링 부분은 아래와 같습니다.

구현 특이사항
스트림릿에서 제공하는 dataframe으로 파이프라인 현황과 히스토리를 구현하려고 했으나, 기존에 보내고 있는 형식이 HTML로 고정되어 있어서 화면에도 HTML로 보이게 설정하였고 링크 기능을 추가하기 위해서 HTML로 구현했습니다.
HTML로 만들게 되면 스트림릿 dataframe 기능을 완전히 없어지기 때문에 HTML로 만드는 것은 추천하지 않습니다. 예를 들어 dataframe에서의 ascending/descending 기능을 클릭 한 번으로 변화를 볼 수 있지만 HTML 은 그 기능을 하지 못합니다.
마무리
개선이 끝난 파이프라인 모니터링 서비스의 아키텍처는 아래와 같습니다.

스트림릿과 n8n 도입을 통해 기존 문제점을 모두 해결할 수 있었습니다.
- 관리자가 매주 직접 파이프라인을 확인해야 함
➜ 스트림릿의 도입을 통해 한 화면에서 몰아봄으로써 개별 파이프라인의 상태를 체크하는데 걸리는 시간 감소 - Teams 메세지로 직접 오류 상황을 공유해야 하는 번거로움
➜ AI를 활용한 n8n의 도입으로 인한 워크플로우 자동화로 관리자가 메세지를 작성하지 않아도 됨
Streamlit을 활용하면 비교적 간단하게 구현할 수 있지만, 서비스의 규모에 따라 다양한 기술 스택을 고려할 수도 있습니다.
오늘은 파이프라인 모니터링 시스템 구축하며 겪었던 경험을 공유해 드렸습니다. 모니터링은 장애를 예방하고 성능을 최적화하는 중요한 역할을 하는 만큼 시스템 구축을 통해 한눈에 확인할 수 있다면 서비스 운영을 효율적으로 할 수 있습니다. 여기에 workflow 자동화를 통한 업무 자동화까지 더한다면 더 효과적이고 빈틈없는 모니터링 시스템을 구축할 수 있습니다.
'Tech lab' 카테고리의 다른 글
| PostgreSQL 과 MySQL 특징 및 성능 비교 (2) | 2025.05.23 |
|---|---|
| AI를 제조업에서 사용하다면? (feat. Cropper) (2) | 2025.05.09 |
| n8n에서 파이썬(Python)을 활용하여 데이터파이프라인 구축하기 (1) | 2025.03.28 |


